In this final project, we explore Concrete Jungle’s volunteer data and analyze the journeys volunteers have taken. A volunteer journey refers to the path of interactions of a volunteer with Concrete Jungle. Firstly, we clean and merge data frames and find some irregularities in the data. Then, we model volunteer journeys as a Markov chain and try to predict the next step of a volunteer given her current activity. Finally, we use machine learning algorithms to to group similar volunteer paths and explore their characteristics.
Importing Libraries
Code
# Import packages#| output: falseimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport osimport plotly.express as pximport plotly.graph_objects as goimport plotly.io as pio#pio.renderers.default = "notebook_connected"from keras.models import Modelfrom keras.regularizers import l1from keras.optimizers import Adamfrom keras.layers import Input, Densefrom keras import activationsimport tensorflow as tffrom sklearn.metrics import silhouette_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import NearestNeighbors from sklearn.manifold import TSNEfrom sklearn.decomposition import TruncatedSVDfrom sklearn.cluster import DBSCANfrom sklearn.decomposition import PCAfrom sklearn.cluster import KMeans
A discrete time markov model is a sequence of random variable, known as stochastic process, where the value of the next variable only depends on the value of the current variable.
Let \(\{X_t\}_t\) be a stochastic process that captures the state of the system at time \(t\), and let \(\mathcal{S} = \{x_1, x_2, x_3, x_4, x_5 \}\) be the discrete state space that consists of the five event types: Contact Created, Sign up for events, Cancellations, Donations, and Sign up for adventure picks.
We can model each volunteer’s path \(\{X_t\}_t\) as a markov chain, wherein we assume that a volunteer’s participication in an event at time \(t + 1\) purely depends on their activity at time \(t\).
The markov chain has a one-step memory.
Let \(P\) be the \(5 \times 5\) transition matrix. The probability of going from event \(i\) to event \(j\) can be defined as follows: \[ p_{ij}(t) = \mathbb{P}(X_{t + 1} = x_i | X_t = x_j)\]
# Convert Date into datetime objectfull_journey_df['Date'] = pd.to_datetime(full_journey_df['Date'])
Code
journey_subset = full_journey_df[['hashed_name', 'Date', 'Event_Type']]def event_classification(event):''' A function to broadly classify event types into four categories: 1. Cancellations 2. Sign-Up: Event 3. Sign-Up: Adventure Pick 4. Donation Note: Event_Type == Contact_Created already exists '''ifstr(event).startswith('Cancellation'):return'Cancellation'elifstr(event) =='Sign-Up: Adventure Pick':return'Sign-Up: Adventure Pick'elifstr(event).startswith('Sign-Up:'):return'Sign-Up: Event'else:return eventjourney_subset['Event_Type'] = journey_subset['Event_Type']\ .apply(lambda x: event_classification(x))
Code
# create pivot table with counts of each event by hashed_name and datepivot_journey = journey_subset.pivot_table(index=['hashed_name', 'Date'], columns='Event_Type', aggfunc='size', fill_value=0).reset_index()# group by hashed_name and sum up events for each daygrouped = pivot_journey.groupby('hashed_name').sum().reset_index()
Code
# Set-up data for Markov Chain modeldef conversion_list(x): path_list = x.to_list() conversion ='Sign-Up: Adventure Pick'# If volunteer did not sign-up for adventure pick, end journey with 'Null'if conversion notin path_list: path_list.append('Null')else:passreturn path_listdf_paths = journey_subset.groupby('hashed_name')['Event_Type'].aggregate(lambda x: conversion_list(x)).reset_index()df_paths = df_paths.rename(columns={'Event_Type': 'path'})list_of_paths = df_paths['path'].to_list()
Code
# Markov Chain Modelclass MarkovChain:''' Motivation: https://towardsdatascience.com/marketing-channel-attribution-with-markov-chains-in-python-part-2-the-complete-walkthrough-733c65b23323 '''def__init__(self, list_of_paths):# stores all paths taken by volunteers/donorsself.paths = list_of_paths# stores all unique events in the list of pathsself.states = ['Contact_Created', 'Sign-Up: Event', 'Cancellation', 'Donation', 'Sign-Up: Adventure Pick', 'Null']def conversion_rate(self): total_conversion =sum(path.count('Sign-Up: Adventure Pick') for path inself.paths) base_conversion_rate = total_conversion /len(self.paths)returnprint(f"The total conversion rate is:{total_conversion}, and the base conversion rate is: {base_conversion_rate}")def transition_states(self):''' A function that takes the list of paths and returns a dictionary that represents the transition counts between every event pair in the list. '''# Initialize a dictionary with all possible transition states transition_states = {x +'>'+ y: 0for x inself.states for y inself.states}# Loop through each possible state and count the transitionsfor state inself.states:# Skip the 'Null' eventif state =='Null':continue# Loop through each user pathfor path in list_of_paths:# If the event is in the path, count its transitionsif state in path:# Find all occurrences of the event in the path indices = [i for i, s inenumerate(path) if s == state]# Increment the transition count for each occurrence of the eventfor index in indices:if index <len(path) -1: transition_states[path[index] +'>'+ path[index +1]] +=1return transition_statesdef transition_prob(self, transition_dict):# Calculate the transition probabilities for each state trans_prob = {}for state inself.states:# Skip 'Null' stateif state =='Null':continue# Calculate the total number of transitions involving the current channel total_transitions =sum([count for key, count in transition_dict.items() if key.startswith(state +'>')])# Calculate the transition probabilities for each transition state involving the current channelfor key, count in transition_dict.items():if key.startswith(state +'>'): trans_prob[key] =float(count) / total_transitionsreturn trans_probdef transition_matrix(self, transition_probabilities):# Set up the transition matrix transition_matrix = pd.DataFrame(index =self.states, columns =self.states)for state inself.states: transition_matrix[state] =0.00 transition_matrix.loc[state] =0.00 transition_matrix.loc[state, state] =1.0if state =='Null'else0.00for key, value in transition_probabilities.items(): current_state, next_state = key.split('>') transition_matrix.at[current_state, next_state] = valuereturn transition_matrixdef fit(self): trans_states =self.transition_states() trans_prob =self.transition_prob(trans_states) trans_matrix =self.transition_matrix(trans_prob)return trans_matrix
Markov Model Results
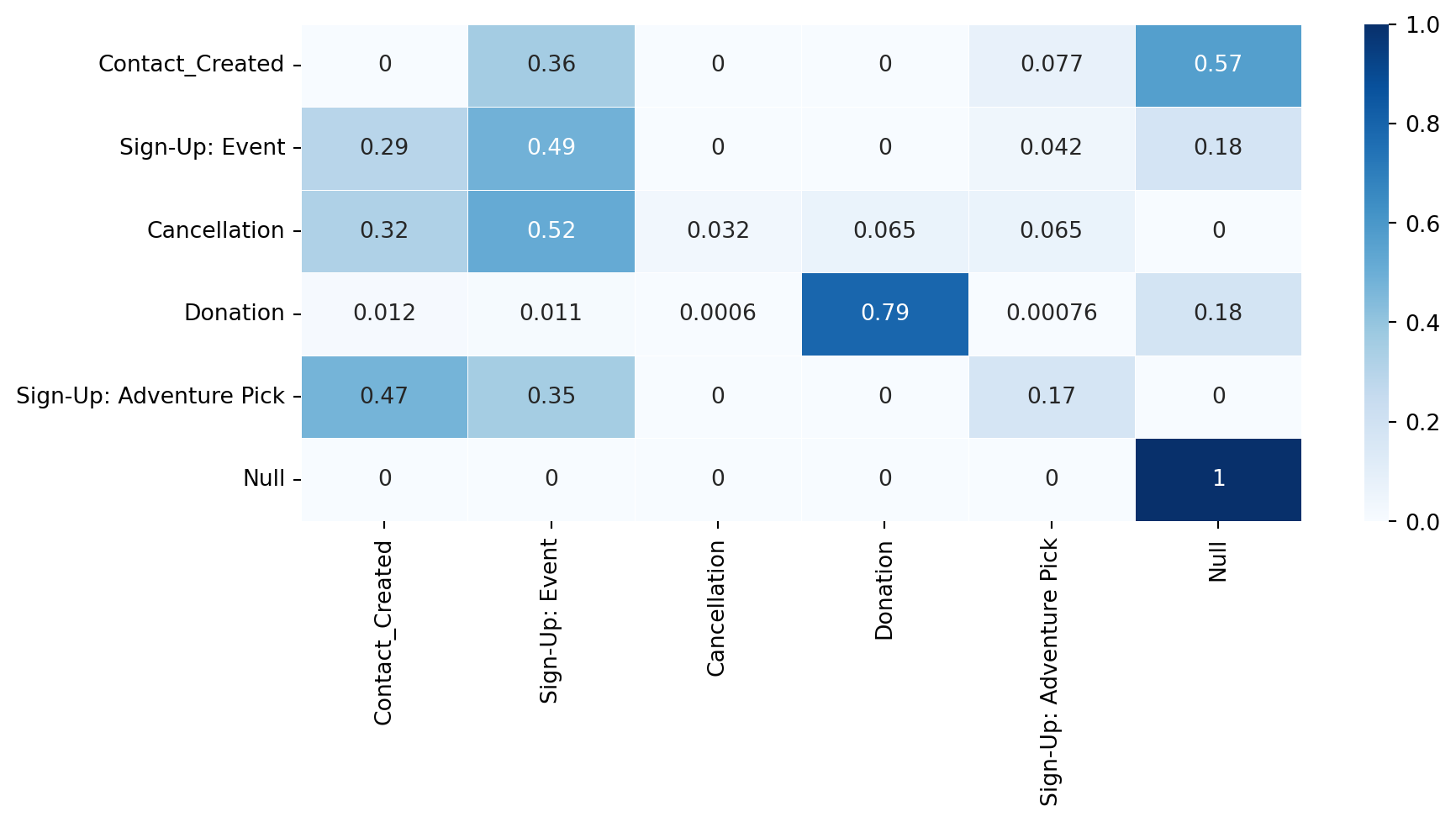
The results from the estimated transition matrix are as follows:
import seaborn as sns model1 = MarkovChain(list_of_paths).fit()fig, ax = plt.subplots(figsize = (10, 4))# Displaying dataframe as an heatmap sns.heatmap(model1, cmap ="Blues" , linewidths =0.30, annot =True)
<AxesSubplot: >
Assuming that volunteer paths follow a Markov process, we can claim that a there is a 40% chance that volunteers who create contact will sign up for an event at the next time period. Moreover, there is only a 7.5% chance that they will sign up for an adventure pick after creating contact, and a 45.6% chance that they will be inactive after contact creation.
Similarly, if a volunteer sign up for an adventure pick, there is a 17% probability that they will sign up for an adventure pick in the next time period. Interestingly, there is a 77% probability that an individual who has donated will donate again at the next time step.
Deep Clustering
We take two approaches to study clusters of volunteer journeys:
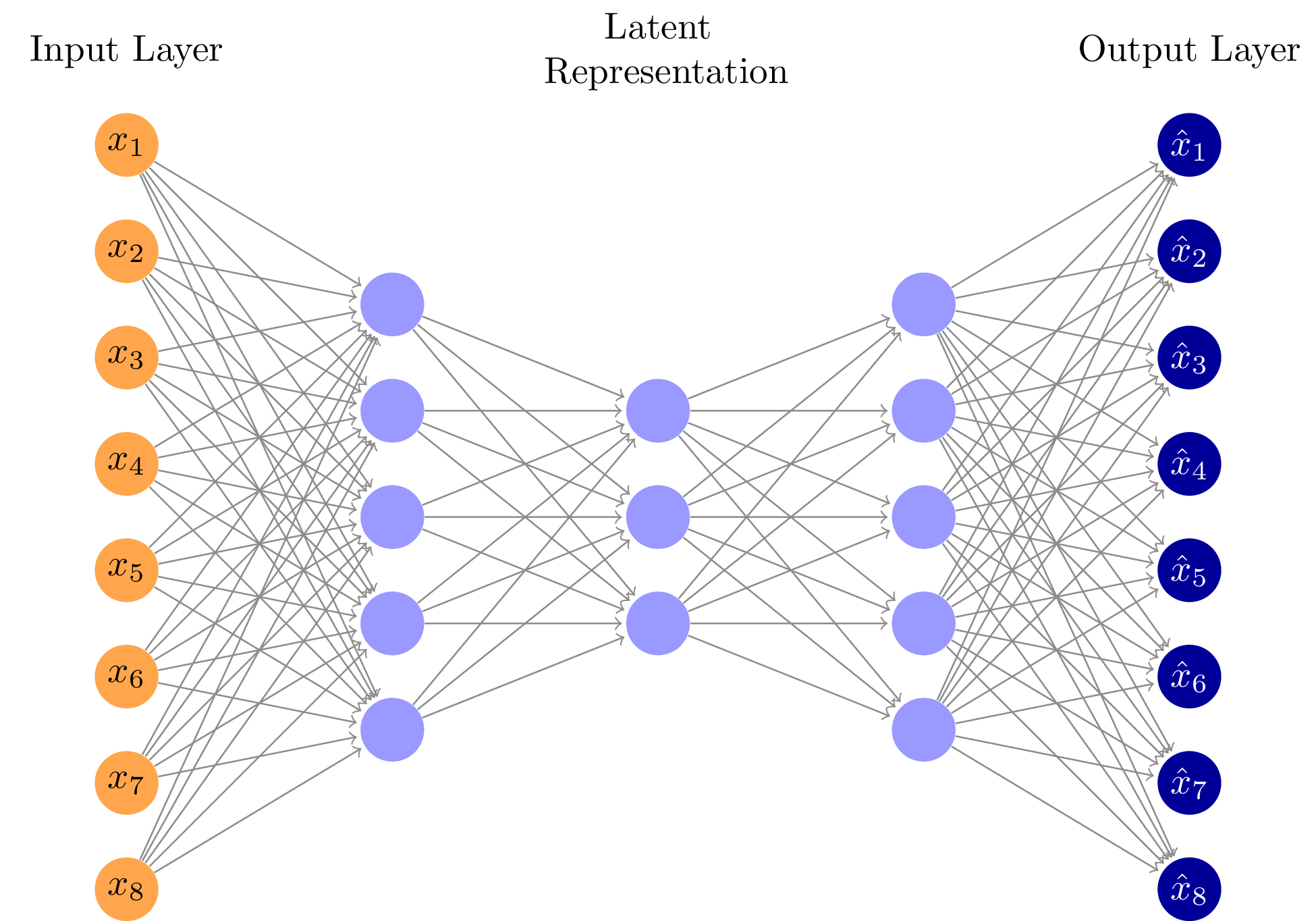
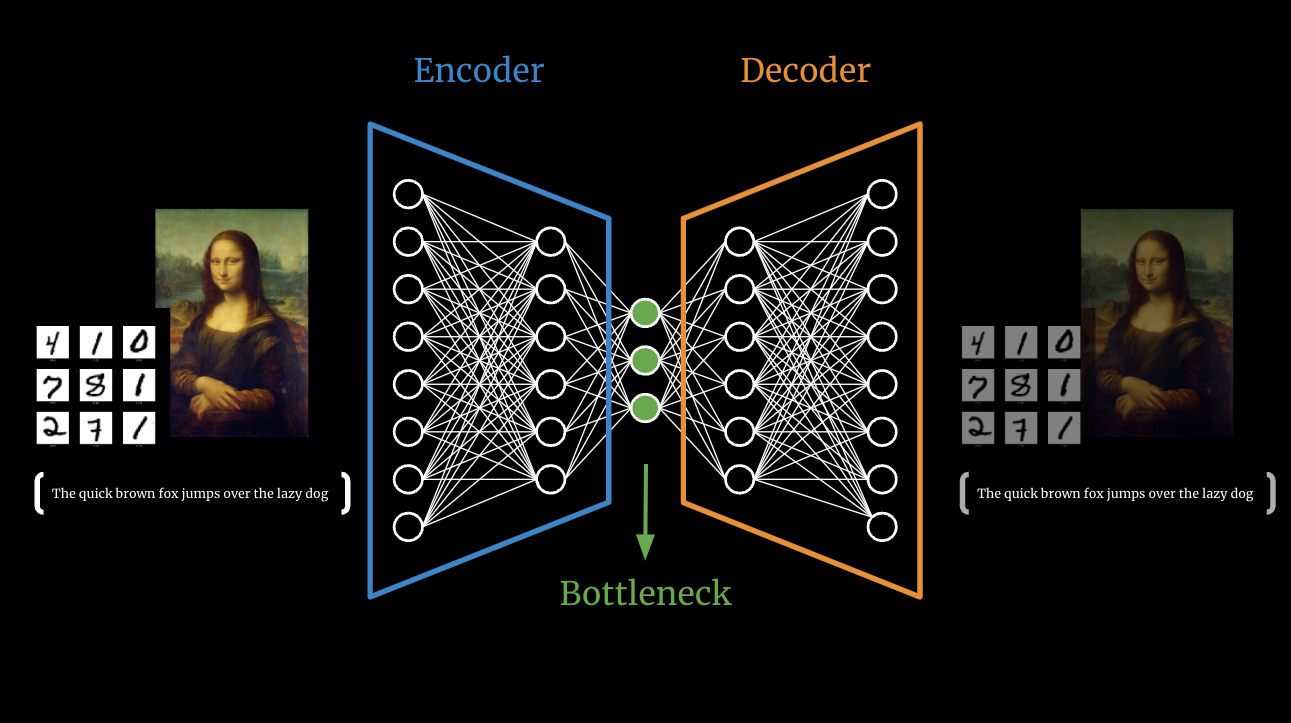
Autoencoder + K-Means: We use an Autoencoder neutral network to conduct dimesionality reduction and fit a K-Means clustering algorithm to the encoded data. Next, we feed the low dimesional cluster centers into the decoder to get a full dimensional journey image. The journey images is representative of the standard journeys in the cluster and the autoencoder helps stitch the low dimensional data into the original shape and visualize it.
Truncated SVD + DBSCAN: Density-based spatial clustering of applications with noise (DBSCAN) is a density based clustering algorithm that groups points that are closely packed together. We use a dimesionality reduction technique called Truncated SVD to reduce the journey image sparse matrix. Next, we run the DBSCAN clustering algorithm on the low dimesional data. DBSCAN model can be treated as a predictive model to predict the cluster label of each volunteer journey.
We use a deep autoencoder clustering algrorithm to identify groups of volunteers who have taken a similar path to interact with the organization. In order to perform the analysis, we take the following steps: 1. Represent each volunteer’s journey as a 2D image. - First, we convert each activity into a \((1 \times 5)\) vector like \([0, 0, 1, \dots, 0]\). The vector values represent whether a given activity has been done \((1)\) or not \((0)\). - Next, we expand the vector into a matrix of ordered activties. A journey path for a volunteer \(i\) might look like:
We create a \((24 \times 5)\) matrix for each journey as 24 is the optimal upper limit on path lengths (excluding some outliers). A zero row vector represents the remaining row for volunteers with less than \(24\) steps. We have a total of \(1283\) volunteers with path length less than 24. So, full journey of each volunteer can be stored in a \((1283 \times 24 \times 5)\) tensor.
We train an autoencoder neutral network that can learn to compress each image through its encoder network and recreate the original sized image through its decoder network. The reduced form images from the encoder are fed into a K-Means clustering algorithm to estimate the groups of similar volunteer paths. Lastly, we use the decoded network to transform the cluster centers back into their original shape and use sanky plots to visualize the standard paths taken by the volunteers.
Code
full_journey_df['Event_Type'] = full_journey_df['Event_Type'].apply(lambda x: event_classification(x))# % of NA values in each column for each event typedef na_percent(x):return (x.isnull().sum() *100) /len(x)percent_missing = full_journey_df.groupby('Event_Type').agg(na_percent)# Choose all columns where percentage of NA values is less than 30%notna_columns =list(percent_missing[percent_missing <30].dropna(how ='all', axis =1).columns) # convert to list# Remove redundant or unwanted columnsremove_columns = ['Unnamed: 0.1', 'Unnamed: 0','Earliest sign up', 'Most recent sign up', 'Event Roles', 'Event Type','Role Type', 'Event Role Name (for confirmation automation)', 'Event Time', 'Event Lead First Name','Role', 'Email Confirmation Sent','Total Amount', 'Total donation', 'Total cancellation', 'Total number of sign up', 'Location Name', 'Event Date (For Instruction Emails)']notna_columns = [col for col in notna_columns if col notin remove_columns]notna_columns.append('Event_Type')journey_df = full_journey_df[notna_columns]hashed_names = journey_df['hashed_name'].unique()event_types = journey_df['Event_Type'].unique()event_type_indices = {event_type: i for i, event_type inenumerate(event_types)}#Re-arrange Columnspivot_journey = pivot_journey[['hashed_name', 'Date', 'Sign-Up: Event', 'Contact_Created', 'Donation', 'Cancellation','Sign-Up: Adventure Pick']]# Maximum steps taken on a pathmax_path_length =max(len(x) for x in list_of_paths)
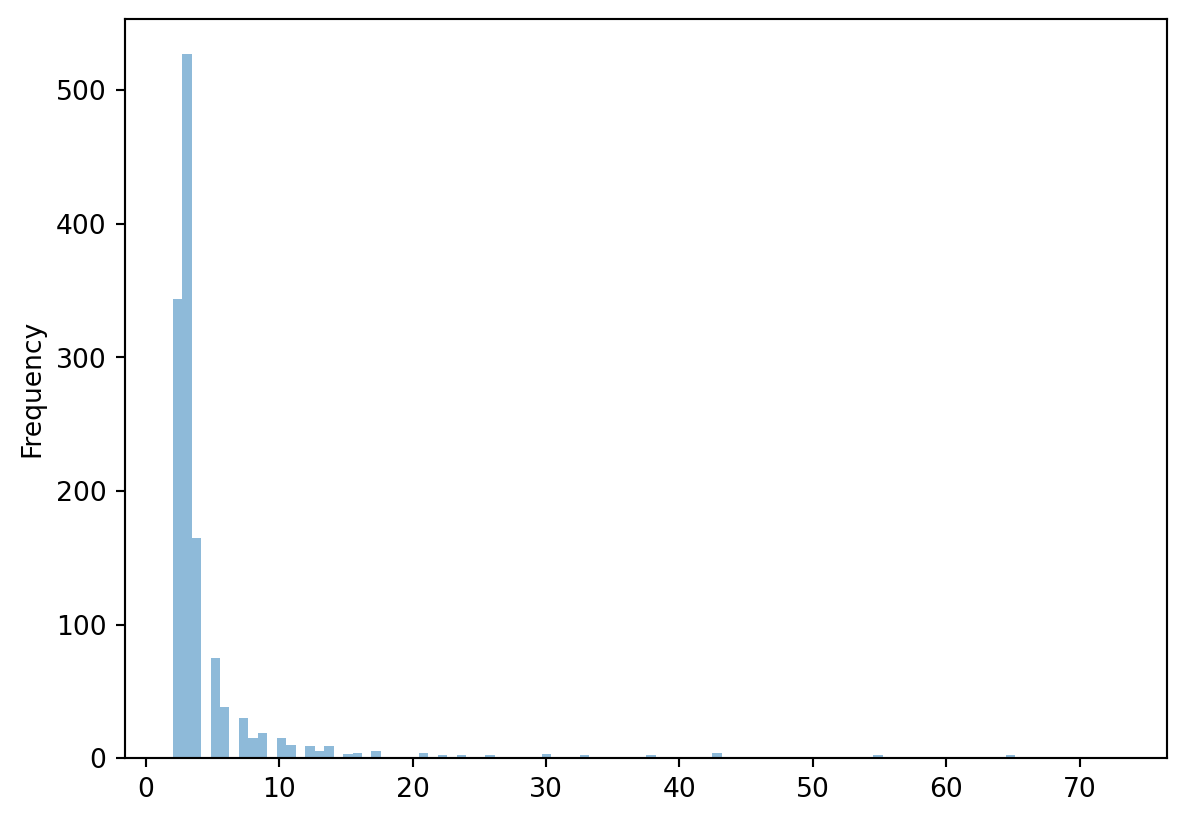
The range of path length is 107 with a mean of 5, and a median of 3. We can see the the path count is skewed to the right. Some of the highest path lengths can be attributed to recurring donation payments. Next, we exclude the only donors to get a sense of the average path length.
Code
Donation ='Donation'Null ='Null'# New column `Only_Donor` stores 1 if volunteer has only donated, else 0df_paths['Only_Donor'] = df_paths['path']\ .apply(lambda x: 1ifset(list(x)) == {'Donation', 'Null'} else0)donor_list_of_path_df = df_paths[df_paths['Only_Donor'] ==1]events_list_of_path_df = df_paths[df_paths['Only_Donor'] ==0]# Visualize the distribution of path lengthsevents_list_of_path_df['count'].plot.hist(bins=100, alpha=0.5)
<AxesSubplot: ylabel='Frequency'>
We drop any volunteer journeys with path size greater than 25. We remove the outliers as they are increasing the dimesions of the data (\(\text{Max Path Length} \times \text{\# Events}\)), and distorting the clustering analysis.
# Create a zero tensor with dimensions # (unique hashed_name) x (max path length) x (number of events)tensor = np.zeros((len(events_list_of_path_df), max(events_list_of_path_df['count']), len(event_types)))for i, name inenumerate(events_list_of_path_df['hashed_name']): name_event = pivot_journey[pivot_journey['hashed_name'] == name][event_types].values num_events = name_event.shape[0] tensor[i, :num_events, :] = name_event
Code
# Flatten 3D tensor into 2DX = tensor.reshape((len(tensor), np.prod(tensor.shape[1:])))X_train, X_test = train_test_split(X, test_size=0.2)tensor_train, tensor_test = train_test_split(tensor, test_size=0.2)X.shape, X_train.shape, X_test.shape
# Extracting the encoder networkencoder = Model(input_layer, latent_layer)encoder.compile(optimizer = Adam(learning_rate =1e-5), loss=tf.keras.losses.MeanSquaredError(), metrics = ['accuracy'])# load the weights created by the autoencoder encoder.load_weights(os.path.join(os.path.curdir, 'ae_weights.h5'), by_name =True)# low dimesion encoded data for KMeans()encoded_data = encoder.predict(X)
# Extracting the decoder networkdecoder = Model(latent_layer, output_layer)encoder.compile(optimizer = Adam(learning_rate =1e-5), loss=tf.keras.losses.MeanSquaredError(), metrics = ['accuracy'])# load the weights created by the autoencoder decoder.load_weights(os.path.join(os.path.curdir, 'ae_weights.h5'), by_name =True)
Code
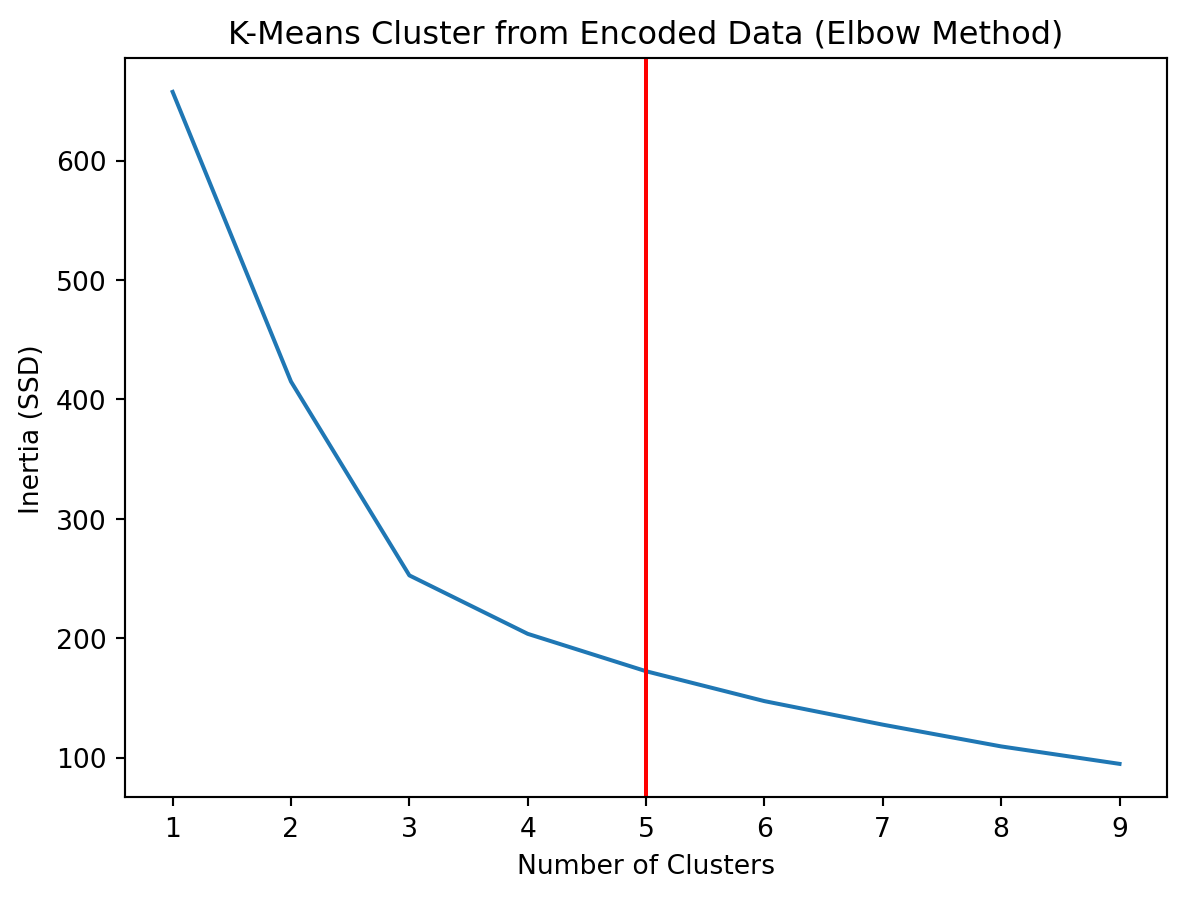
# Choose optimal number of clusters by visual inspection (Elbow Method)#| warning: falseinertia = []for i inrange(1, 10): km = KMeans(n_clusters = i, random_state=0).fit(encoded_data) inertia.append([i, km.inertia_])# Plot Inertiainertia = np.array(inertia).reshape(-1, 2)plt.plot(inertia[:, 0], inertia[:, 1])plt.axvline(x =5, c ='red')plt.xlabel('Number of Clusters')plt.ylabel('Inertia (SSD)')plt.title('K-Means Cluster from Encoded Data (Elbow Method)')
Text(0.5, 1.0, 'K-Means Cluster from Encoded Data (Elbow Method)')
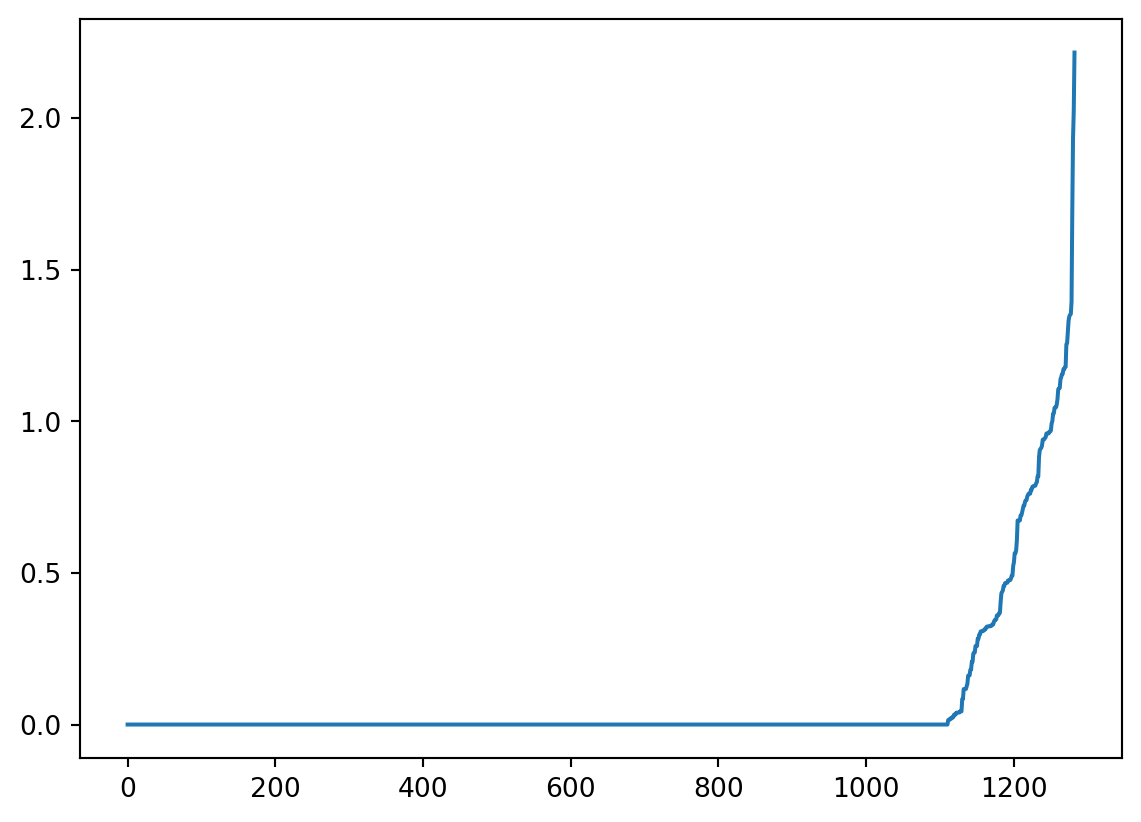
Next, we consider all DBSCAN fits with parameter eps from 0.5 to 1.5 and select the one with the best silhouette score. The silhouette score compares the mean intra-cluster distance to the mean nearest cluster distance and ranges from -1 to 1. While -1 represent the worst score, 1 represents the best possible score. If the data has more than 2 dimensions, choose MinPts = 2 * dimensions (Sander et al., 1998). The DBSCAN algorithm can be used as a predictive technique to cluster future journeys.
# Using Nearest Neighbors to find the average distance between data points# Finding the Nearest Neighborsneighbors = NearestNeighbors(n_neighbors =10*2) nbrs = neighbors.fit(X_svd)distances, indices = nbrs.kneighbors(X_svd) # Sort and Plot the Distances Resultsdistances = np.sort(distances, axis =0) distances = distances[:, 1]plt.plot(distances) plt.show()
Best silhouette_score: 0.6985920850838758
eps: 0.7300000000000002
Code
# DBSCAN Implementation# fitting the modeldbscan = DBSCAN(eps = optimal_eps, min_samples =10*2).fit(X_svd) labels = dbscan.labels_# Plotting DBSCAN clustersX_svd_df = pd.DataFrame(X_svd)X_svd_df['labels'] = pd.Series(labels)pca = PCA(n_components =3)PCs_3d = pd.DataFrame(pca.fit_transform(X_svd_df.drop(["labels"], axis=1)))PCs_3d.columns = ["PC1_3d", "PC2_3d", "PC3_3d"]plot_DBSCAN = pd.concat([X_svd_df, PCs_3d], axis=1, join='inner')fig = px.scatter_3d(plot_DBSCAN, x ="PC1_3d", y ="PC2_3d", z ="PC3_3d", color ="labels")fig.update_layout(title ='DBSCAN Cluster Representation in 3D', xaxis_title ='PC1', yaxis_title ='PC2', height=600)fig.show()
The DBSCAN algorithm clusters the reduced data into ten clusters with labels \(0, 1, \dots 10\), whereas the outliers are labelled as \(-1\). Out of all the journeys, 218 are labelled as outliers and the rest are clustered into three groups. The DBSCAN clustering algorithm is applied on a \(10\)-dimesional reduced data. In order to visually represent the cluster points, the data is further reduced to \(2\)-dimesions (using PCA). This might be a reason that the clusters appear to be overlapping. Lastly, the silhouette score of the DBSCAN algorithm is \(0.698\).
Sander, J., Ester, M., Kriegel, HP. et al. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and Its Applications. Data Mining and Knowledge Discovery 2, 169–194 (1998). https://doi.org/10.1023/A:1009745219419